VARNISH AI ACCELERATOR
Speed up AI training and inference. Maximize your GPU investment
High-performance caching infrastructure for large-scale AI training and inference workloads. Varnish ensures your GPUs always have fast access to the data they need — reducing wait times, cutting unnecessary data transfer costs, and helping you get more out of your investment.


Compute has outpaced storage and network
GPU clusters can scale faster than the data infrastructure around them. The bottleneck is no longer only compute availability. It is how quickly datasets, model artifacts and training data can reach the workloads that need them.
Traditional high-performance storage can reduce I/O bottlenecks, but at high cost and with less flexibility. Object storage prioritizes cost and scale, but introduces latency, throughput, and compatibility challenges. Varnish bridges that gap.
Single TCP connection to a hyperscaler bucket can cap around 2–3 Gb/s.
First-byte latency from object storage can be around 120 ms.
A modern AI training node can need 1.5–3 GB/s of sustained dataset throughput.
GPUs wait for data
Expensive compute sits idle while workloads wait for bytes from object storage.
Repeated reads increase cost
Training runs read the same datasets repeatedly across epochs, increasing storage backend pressure and transfer cost.
Object storage is not built for GPU throughput
Object storage is durable and scalable, but not optimized to feed large GPU clusters at sustained high throughput.
Performance storage is expensive to scale
Keeping all data on high-performance storage can be costly and inflexible at AI infrastructure scale, especially when large existing datasets are expensive to migrate.
Why it's different
Why tiered caching changes the economics of AI infrastructure
AI infrastructure teams often face a bad trade-off: keep or migrate to expensive high-performance storage, or accept the latency and throughput limits of cheaper object storage. Varnish adds a caching layer between storage and compute so hot data can move faster without making every byte expensive or forcing teams to migrate large existing datasets.
|
VARNISH TIERED CACHING Keep cold data cheap and hot data fastVarnish adds one or more cache tiers between object storage and compute. Frequently accessed data moves closer to the workload, while scalable origin storage remains cost-efficient. |
|
|---|---|
| ✓ |
Fetch once, serve repeatedly |
| ✓ |
Reduce origin reads and egress pressure |
| ✓ |
Keep hot data near GPU workloads |
| ✓ |
Improve GPU utilization |
| ✓ |
Scale performance without putting all data on premium storage |
✓ Capacity to performance gradient
|
Traditional high-performance storage Fast, but expensive to scale.Purpose-built performance storage can reduce bottlenecks, but scaling it across large datasets drives major cost and complexity. |
|
|---|---|
| ⚠ |
High storage cost at scale |
| ⚠ |
Hard to justify for cold data |
| ⚠ |
Expensive to replicate across locations |
| ⚠ |
Forces spend into storage over compute |
|
Object-storage-only architecture Scalable, cheap but too slow.Object storage works well for capacity and durability, but AI workloads often need low-latency, high-throughput data access close to GPU clusters. |
|
|---|---|
| ⚠ |
Latency between storage and compute |
| ⚠ |
Throughput limits under heavy parallel reads |
| ⚠ |
Repeated origin reads across epochs |
| ⚠ |
Egress and transfer cost exposure |
What it does
Fetch once. Cache locally. Serve at high speed.
Varnish Tiered Storage sits between your object storage and your compute. It pulls data from cheap, scalable cloud, on-prem or hybrid object storage — once — then keeps the hot data in fast local cache close to compute, served at sub-millisecond latency and ultra-high throughput (terabit-range). Multiple cache tiers let you balance cost and performance across your workload: hottest data lives at the edge, cooler data steps back, scalable origin stays cheap but durable. You pay for fast storage only where you need it, without staggering data-transfer costs.
Cost benefits
Cheap, scalable origin storage
Minimize transport costs
Reduce repeated origin reads & egress.
Increase GPU utilization
Shorter training cycles, higher ROI.
Performance outcomes
Accelerate AI training cycles
Remove inference cold starts
Near-instant startup for data-heavy inference workloads. See Varnish Virtual Registry
Proof at scale
Higher GPU utilization without adding more GPUs
A global high-frequency trading firm used Varnish Tiered Storage to accelerate movement of exabyte-scale data into globally distributed GPU clusters. Removing data bottlenecks while improving use of existing compute.
Thousands of GPUs Exabyte-scale storage Three globally distributed clusters
25% → 75%
GPU utilization
More compute time spent on training, less time waiting on storage.
3x
More effective use of existing compute
Without investing in more GPUs.
99.8%
Cache hit rate
Cache of last resort — reduced origin reads and egress.
1.6 Tbps
Edge-tier throughput
Terabit-range delivery close to compute.
Our purpose-built storage could not keep our GPUs fed. Varnish Tiered Storage fixed that bottleneck, and cut our storage bill while doing it.

Global high-frequency trading firm

Capabilities
Built for real-world AI infrastructure
Varnish AI Accelerator is built for when datasets are large, reads are parallel and compute needs predictable access to data.
01
AI-scale caching and prefetch |
Designed for multi-terabyte datasets, high-throughput parallel reads and repeated access patterns common in training and inference. Configure prefetch and prefill so data is staged before compute requests it.
|
02
Flexible architecture and access |
Works with S3-compatible or HTTP origins across cloud, on-prem and hybrid environments, using commodity infrastructure with low CPU overhead. Mount cache as a filesystem with POSIX-compatible access for existing pipelines.
|
03
Customizable cache policy |
Tune TTLs, eviction rules and tier-promotion logic to match workload patterns, dataset temperature and infrastructure cost goals. # cache policy:
|
04
Deep observability and control |
Track cache hit rates, dataset throughput, and real-time operational behavior. Maintain total control over your pipelines with advanced invalidation mechanisms, rulesets, and performance logging metrics.
|
05
Cluster-scale operations |
Support highly distributed environments with rock-solid, consistent data access patterns across computing resources. Keep nodes synchronized flawlessly whether scaling across single clusters, multi-cloud spaces, or global regions.
|
Built for data-heavy AI environments
Varnish AI Accelerator fits environments where data has to move fast, compute has to stay fed and storage efficiency still matters.
GPU farms and neo-clouds
Maximize GPU ROI with faster data access for shared training clusters, low-latency model serving and multi-tenant infrastructure.
Autonomous systems
Accelerate sensor-heavy training pipelines and edge model delivery for autonomous vehicles, robotics and real-time decision systems.
Telcos and mobile networks
Support AI across distributed network environments where low latency, scale and data control all matter.
Financial services AI infrastructure
Accelerate AI, analytics and trading workloads by keeping hot data closer to compute, reducing repeated data movement and improving performance across distributed environments.
Media and entertainment
Move large media assets faster for generative AI, rendering, VFX and production workflows.
Healthcare and life sciences
Speed up data-intensive clinical, genomic and scientific workflows while keeping more control over sensitive data paths.
Technical architecture
A tiered data path for AI workloads
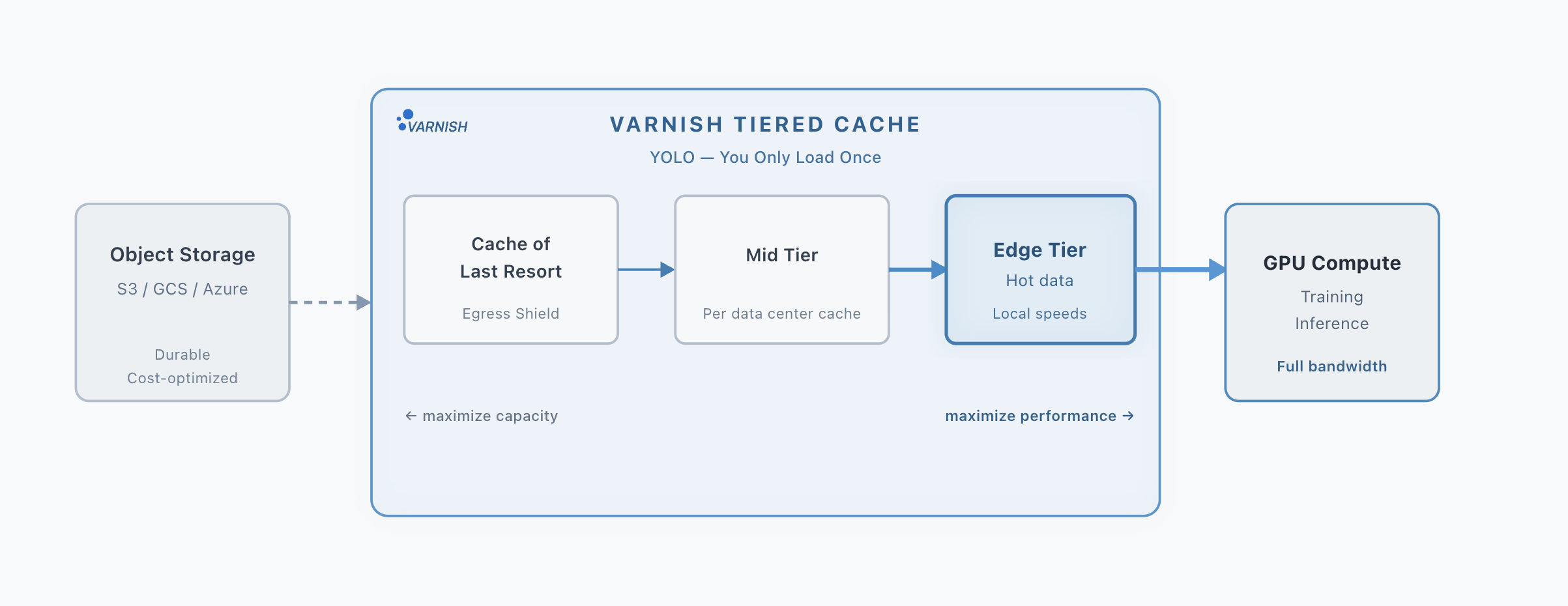
Varnish Tiered Storage creates a capacity-to-performance gradient between object storage and GPU compute. Cold data stays durable and cost-efficient. Hot data moves closer to the workloads that need it.
Object Storage
S3 / GCS / Azure / on-prem / hybrid
Cache of Last Resort
Capacity-biased cache close to bucket. Reduces origin reads.
Midtier Cache
Balanced cache per fabric. Collapses edge requests upstream.
Edge Cache
Performance-first cache near GPU. Serves hot shards.
GPU Compute
Training, inference, and data pipelines
The cache is lossy on purpose
Varnish Enterprise treats upstream storage as the source of truth. Cache nodes are allowed to forget. If cached content is lost, the next request refetches it from the tier above. This avoids time-consuming RAID-style rebuilds and helps keep reads and writes fast under heavy churn.
Designed around the fabric boundary
Edge caches can sit close to GPU fabric while midtier caches remain on standard Ethernet, helping teams reserve expensive high-performance network capacity for compute.
Stop wasting GPU capacity
Varnish AI Accelerator helps teams reduce data bottlenecks across training, inference and large-scale AI infrastructure.
